Image Segmentation And Classification
4 previous year questions.
High-Yield Trend
Chapter Questions 4 MCQs
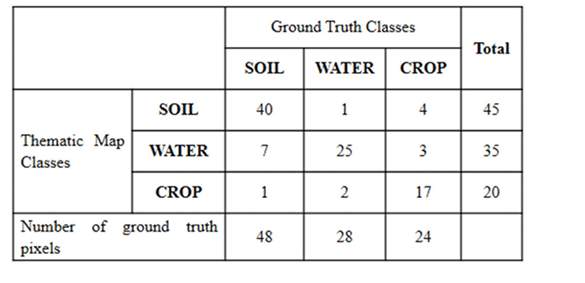
(i) Classification
(ii) Training
(iii) Accuracy assessment
(iv) Radiometric/geometric correction
About Image Segmentation And Classification - GATE-GE
Image Segmentation And Classification is a vital chapter for GATE-GE aspirants. Mastering the concepts covered in this chapter is essential for securing a top rank.
By rigorously practicing the previous year questions associated with this chapter, you can identify high-yield topics, understand the examiner's perspective, and boost your confidence during the actual exam.
Frequently Asked Questions
Why focus on Image Segmentation And Classification PYQs?
Analyzing PYQs for this specific chapter reveals the most frequently tested concepts and the typical complexity of questions, allowing you to tailor your study plan efficiently.
How to best use this analysis?
Review the topic breakdown to see which sub-topics within Image Segmentation And Classification carry the most weight. Then, tackle the questions iteratively to solidify your understanding.